Method
We leverage End-to-end RL to control the robot. We use separate encoders for multi-modal inputs to get domain-specific features and use a MLP to get the value or action distribution from concatenated features.
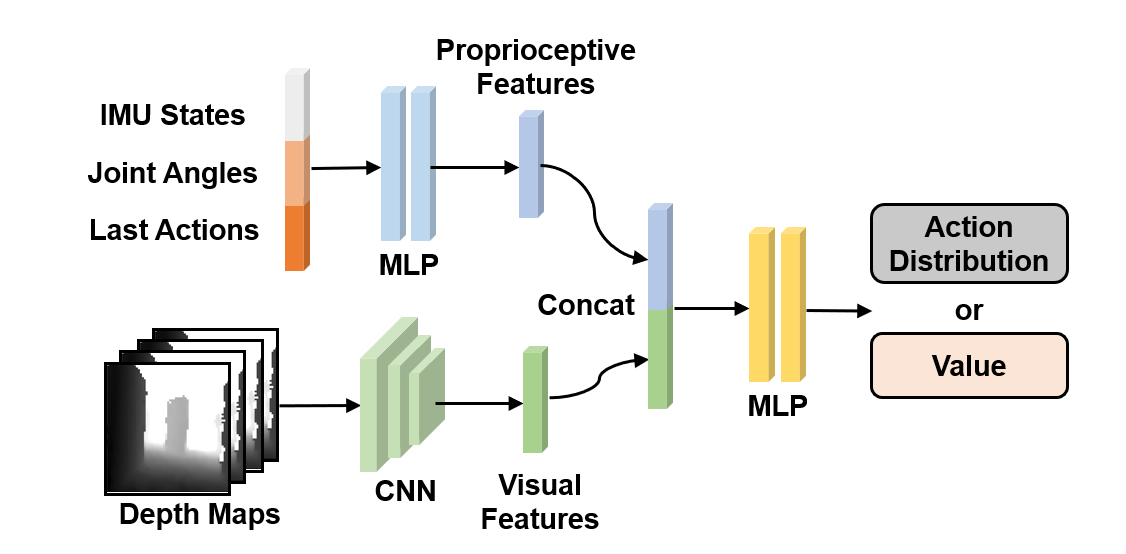
Challenges of sim-to-real regarding policy execution latency in the real robot can be dealt with by randomizing the various modeled latencies in the simulation during training. We propose to address this latency in deploying learned multi-modal policy with Multi-Modal Delay Randomization (MMDR). To simulate the proprioceptive latency, we sample a proprioceptive delay and use linear interpolation to calculate the delayed observation from two adjacent states in the entire buffer with the sampled delay. To simulate the perception latency for visual observation at a lower frequency, we obtain the simulated visual observation at every control step and store them in the the visual observation buffer maintaining visual observation in the near past. As illustrated in the following figure, we store the most recent 4k depth maps as our visual observations buffer, split the whole visual observation buffer into four sub-buffers, then sample one depth map from each sub-buffer to create the visual input with randomized latency.
